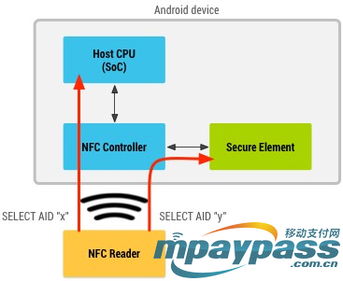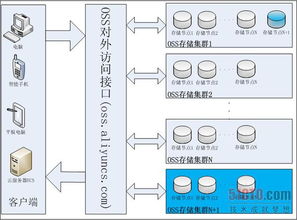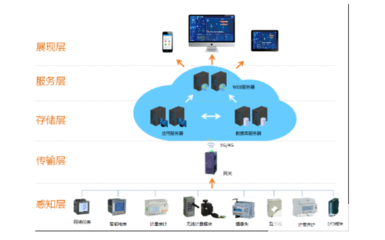
隨著大數據和云計算技術的飛速發展,傳統的數據存儲和處理方式已難以滿足現代企業日益增長的需求。分布式數據存儲與并行處理技術應運而生,成為構建高效、可擴展數據處理和存儲服務的核心解決方案。
一、分布式數據存儲的基本原理與優勢
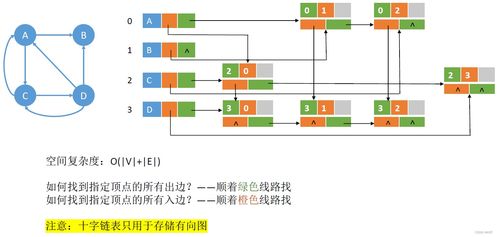
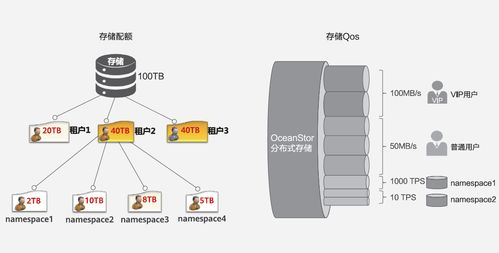
分布式數據存儲通過將數據分散存儲在多個節點上,實現數據的冗余備份和負載均衡。其核心原理包括:
- 數據分片:將大數據集分割成多個小塊,分布到不同的存儲節點。
- 冗余機制:通過副本或糾刪碼技術,確保數據的高可用性和容錯能力。
- 一致性協議:如Paxos或Raft,保障分布式系統中數據的一致性。
優勢體現在:
- 高可擴展性:可輕松添加節點以應對數據增長。
- 高可靠性:單點故障不會導致數據丟失。
- 成本效益:利用普通硬件構建大規模存儲系統。
二、并行處理技術的關鍵組件
并行處理旨在通過多個處理單元同時執行任務,顯著提升數據處理效率。關鍵組件包括:
- 任務并行化:將大型任務分解為子任務,分配給不同處理器。
- 數據并行化:對數據集進行分區,每個處理器處理一部分數據。
- 分布式計算框架:如Apache Hadoop和Apache Spark,提供底層支持。
并行處理的優勢:
- 高性能:大幅縮短數據處理時間,尤其適合實時分析。
- 資源優化:充分利用計算資源,避免瓶頸。
- 靈活性:支持批量處理和流式處理等多種模式。
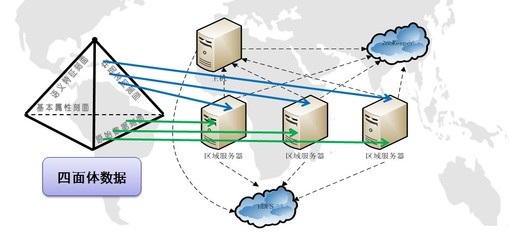
三、分布式數據存儲與并行處理的結合應用
將分布式存儲與并行處理結合,可構建強大的數據處理和存儲服務。典型應用場景包括:
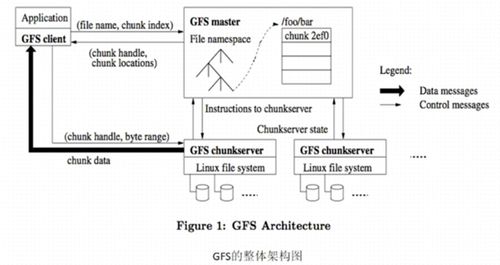
- 大數據分析:企業利用HDFS存儲數據,并通過Spark進行并行計算,實現快速洞察。
- 實時流處理:如Kafka與Flink結合,處理高吞吐量數據流。
- 云存儲服務:AWS S3和Google Cloud Storage提供分布式存儲,配合EMR或Dataproc實現并行處理。
四、面臨的挑戰與未來趨勢
盡管分布式數據存儲與并行處理技術已成熟,但仍面臨挑戰:
- 數據一致性與延遲的平衡:在分布式環境中確保強一致性可能增加延遲。
- 安全與隱私:多節點存儲增加了數據泄露風險。
- 運維復雜度:需要專業知識和工具進行管理。
未來趨勢包括:
- AI驅動的優化:利用機器學習自動調整存儲和計算資源。
- 邊緣計算集成:將分布式技術延伸到邊緣設備,支持物聯網應用。
- Serverless架構:進一步簡化部署和管理,提升用戶體驗。
分布式數據存儲與并行處理是構建現代數據處理和存儲服務的基石。通過合理設計和實施,企業能夠實現高效、可靠的數據管理,驅動業務創新和增長。