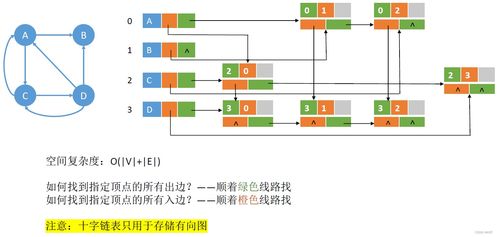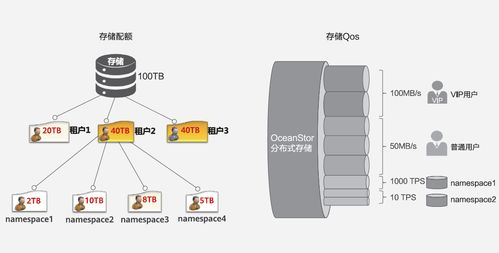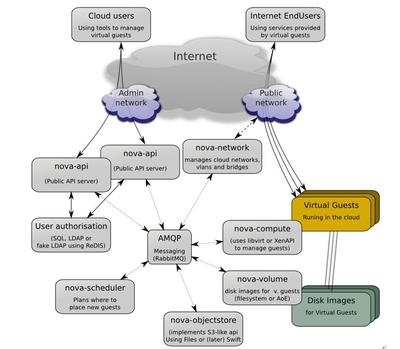
隨著數字經濟的飛速發展,云計算和大數據技術已成為現代科學研究與商業創新的重要驅動力。云計算大數據實驗室作為集成數據處理和存儲服務的前沿平臺,不僅為企業和研究機構提供了高效、可擴展的計算資源,還構建了智能化的數據生命周期管理體系。本文將深入探討云計算大數據實驗室在數據處理與存儲服務方面的架構設計、關鍵技術及實際應用價值。
一、數據處理服務的核心架構
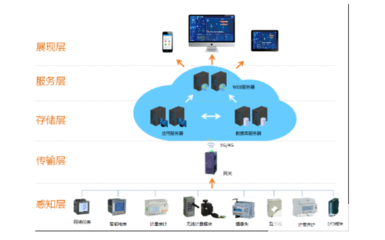
云計算大數據實驗室的數據處理服務基于分布式計算框架,如Apache Hadoop和Spark,實現海量數據的并行處理與分析。通過虛擬化技術,實驗室能夠動態分配計算資源,支持批處理、流處理及交互式查詢等多種計算模式。數據處理流程通常包括數據采集、清洗、轉換、建模與可視化等環節,結合機器學習算法,實驗室可助力用戶從復雜數據中挖掘深層洞察,例如在金融風控、醫療診斷和智能制造等場景中實現預測性分析。
二、數據存儲服務的創新方案
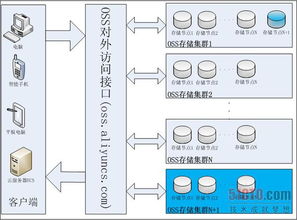
在數據存儲方面,云計算大數據實驗室采用混合存儲架構,融合對象存儲、分布式文件系統和數據庫服務,以滿足不同類型數據的存取需求。對象存儲(如Amazon S3或開源替代方案)適用于非結構化數據的高效存儲;分布式文件系統(如HDFS)則保障大文件的可靠性與可擴展性;而NoSQL與NewSQL數據庫則支持實時事務處理與復雜查詢。實驗室通過數據冗余、備份與加密機制,確保數據安全與合規性,符合GDPR等國際標準。
三、應用場景與業務價值
云計算大數據實驗室的服務已廣泛應用于多個領域。在科學研究中,它加速了基因組學數據分析與氣候模擬;在商業領域,企業利用其實時數據處理能力優化供應鏈、提升客戶體驗。例如,一家電商公司可通過實驗室分析用戶行為數據,實現個性化推薦,從而增加銷售額。實驗室提供成本優化的按需服務,用戶無需前期硬件投入,即可靈活擴展資源,降低總體擁有成本。
四、未來展望與挑戰
盡管云計算大數據實驗室帶來了顯著效益,但也面臨數據隱私、跨云互操作性等挑戰。隨著邊緣計算與AI的融合,實驗室將向更智能、去中心化的方向發展,集成聯邦學習等新技術,以在不集中數據的前提下實現協同分析。云計算大數據實驗室的數據處理與存儲服務正不斷演進,為數字化轉型注入持續動力。
云計算大數據實驗室作為數據處理與存儲的核心樞紐,通過先進架構與創新服務,賦能各行各業實現數據驅動決策。企業與研究機構應積極采用這些服務,以在競爭激烈的數字時代保持領先優勢。