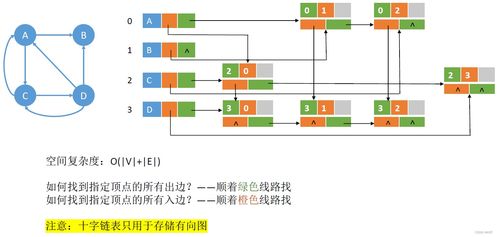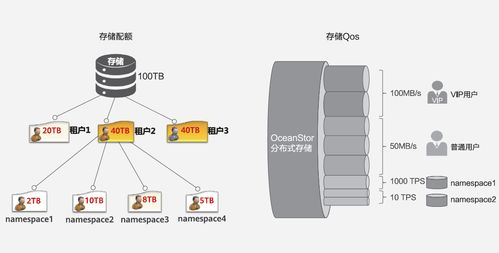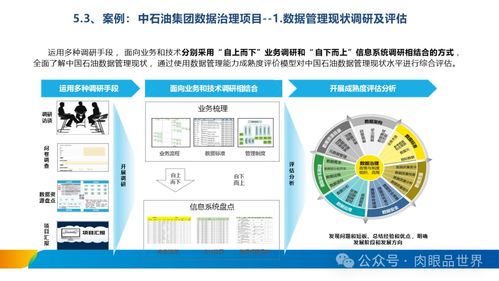
隨著數字化轉型的深入推進,XX集團亟需構建一套高效、安全、可擴展的數據治理體系,以支撐業務創新與決策優化。數據處理與存儲服務作為數據治理的核心組成部分,承擔著數據從采集到應用全流程的管理職責。本方案旨在通過標準化、自動化和智能化的數據處理與存儲服務,全面提升數據質量、安全性和可用性。
一、數據處理服務:構建高效數據流水線
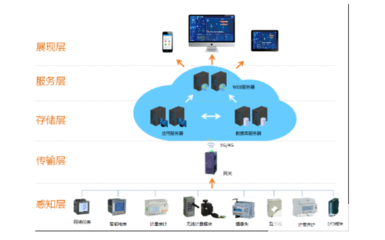
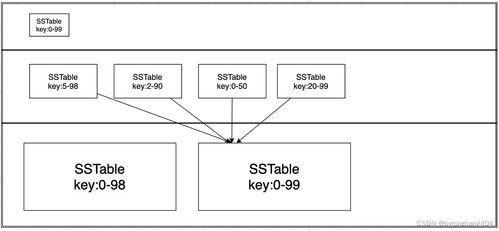
數據處理服務涵蓋數據采集、清洗、轉換、集成與計算等環節。通過統一的數據接口與ETL工具,實現多源異構數據的實時或批量采集,確保數據來源的完整性與一致性。采用數據質量規則引擎,對原始數據進行自動清洗與校驗,消除重復、錯誤及不完整數據,提升數據可信度。引入數據轉換與標準化模塊,將數據統一為規范格式,支持后續分析與應用。在數據計算方面,結合流處理與批處理技術,構建分層數據處理架構,滿足實時分析與離線挖掘的多樣化需求。
二、數據存儲服務:打造安全可靠的數據底座
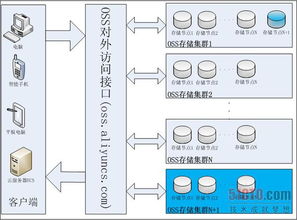
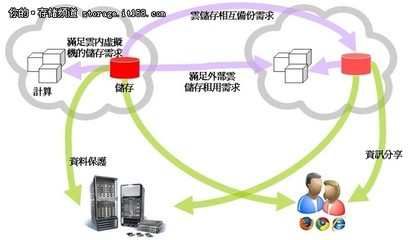
數據存儲服務以分層存儲策略為核心,根據數據熱度與業務需求,設計冷、溫、熱多級存儲方案。熱數據采用高性能分布式數據庫與內存計算技術,保障高并發訪問與低延遲響應;溫數據通過列式存儲或數據湖架構實現高效查詢與分析;冷數據則歸檔至低成本對象存儲,確保長期保存與合規性。強化數據安全機制,通過加密傳輸、訪問控制與審計日志,防止數據泄露與未授權使用。為提升容災能力,建立跨地域數據備份與同步機制,實現業務連續性保障。
三、技術平臺與工具集成
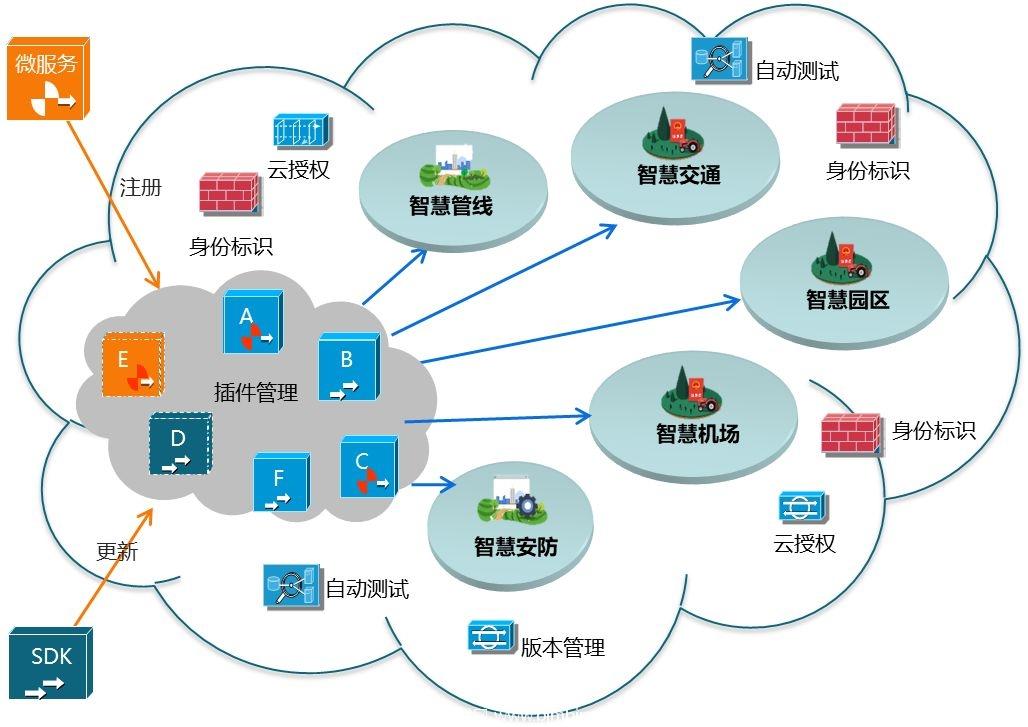
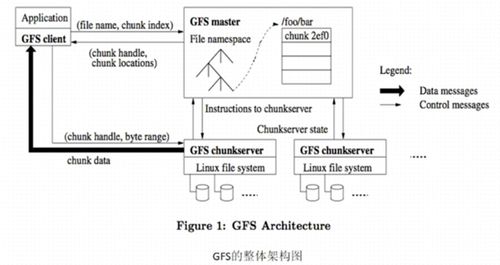
為支撐數據處理與存儲服務的落地,XX集團將引入云原生與大數據技術棧,包括Apache Kafka用于實時數據流處理、Apache Spark進行分布式計算、以及HDFS與云存儲結合的數據湖方案。集成數據目錄與元數據管理工具,實現數據資產的可視化與溯源,輔助數據治理團隊進行生命周期管理。
四、實施路徑與預期成效
本方案擬分三階段推進:第一階段完成基礎平臺搭建與核心數據接入;第二階段擴展數據處理能力與存儲規模;第三階段優化智能運維與數據服務化。通過本方案的實施,預計將實現數據處理效率提升30%,存儲成本降低20%,并為集團數據驅動戰略提供堅實支撐。
數據處理與存儲服務是XX集團數據治理體系的關鍵基石。通過科學規劃與持續迭代,我們將構建一個敏捷、安全、智能的數據基礎設施,賦能業務增長與創新。