在當今數字化時代,手寫文字作為一種傳統的信息記錄方式,依然在眾多領域發揮著重要作用。隨著數據量的爆炸性增長,手寫文字的數字化處理變得日益復雜,以至于傳統軟件工具難以高效應對。這種現象突顯了大數據的核心特征:體積龐大、種類多樣、處理速度要求高。
手寫文字的復雜性體現在多個層面。手寫字體因人而異,識別難度遠超印刷體,需要先進的圖像處理和機器學習算法。大規模手寫文檔的存儲和管理挑戰傳統數據庫的極限,尤其是當涉及歷史檔案或法律文件時。例如,一家醫療機構可能擁有數百萬份手寫病歷,傳統軟件在索引和檢索這些數據時往往效率低下,甚至無法處理。
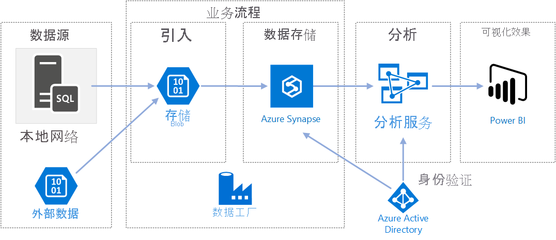
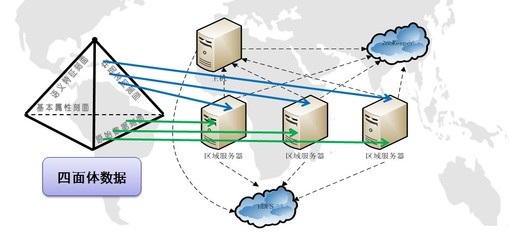
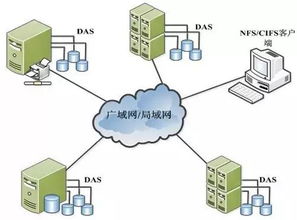
大數據技術的引入為解決這些問題提供了可能。通過分布式計算框架如Hadoop和Spark,系統可以并行處理海量手寫圖像,實現快速識別和分類。同時,云存儲服務如AWS S3或Google Cloud Storage提供了彈性擴展的存儲解決方案,確保數據的安全性和可訪問性。數據處理服務則利用自然語言處理(NLP)和人工智能模型,將手寫文字轉化為結構化數據,便于分析和應用。
大數據在手寫文字處理中的意義不僅限于技術層面。它促進了文化遺產的數字化保護,例如通過掃描和解析古代手稿,保存人類歷史記憶。在商業領域,企業可以分析客戶手寫反饋,獲取更深層次的洞察,從而優化產品和服務。這也帶來了隱私和倫理挑戰,需要制定嚴格的數據治理政策。
手寫文字與大數據的結合展示了現代技術如何應對傳統挑戰。盡管傳統軟件在處理這些復雜數據時顯得力不從心,但大數據的數據處理和存儲服務為我們開辟了新路徑。未來,隨著人工智能和邊緣計算的發展,手寫文字的處理將變得更加智能化,進一步釋放其潛在價值。