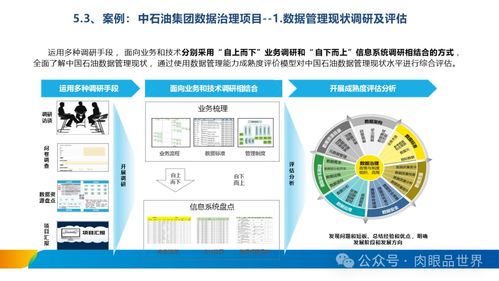
雙11購物節期間,物流訂單激增,實時數據處理與存儲服務成為支撐物流系統穩定運行的關鍵。為應對高峰流量,行業已形成一套成熟的最佳實踐。
一、數據處理服務的關鍵策略
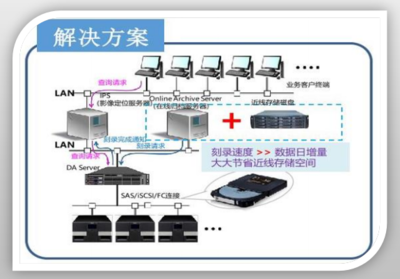
- 流式處理架構:采用Kafka、Flink等流處理技術,實現訂單數據的實時接入與處理,確保毫秒級延遲。通過分布式計算,動態擴展處理能力,支撐每秒數十萬訂單的峰值流量。
- 數據清洗與標準化:在數據入口層部署ETL流程,過濾無效訂單、統一地址格式,并補充地理編碼信息,提升后續物流路由的準確性。
- 實時監控與告警:集成Prometheus、Grafana等工具,對數據處理流水線進行全鏈路監控,設置流量異常、處理延遲等閾值告警,快速定位瓶頸。
二、存儲服務的設計要點
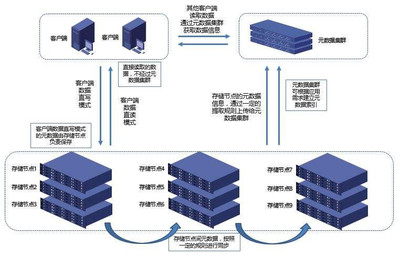
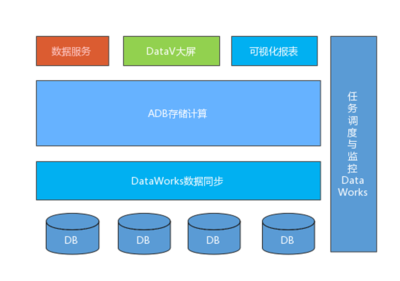
- 多級存儲架構:
- 熱數據存儲:使用Redis或內存數據庫緩存實時訂單狀態,支持高并發查詢。
- 溫數據存儲:通過Elasticsearch索引物流軌跡,實現快速檢索與聚合分析。
- 冷數據存儲:將歷史訂單歸檔至HDFS或對象存儲(如AWS S3),降低成本。
- 數據分區與分片:按時間(如日期)或地域對訂單表進行水平分片,避免單點瓶頸,同時結合讀寫分離策略提升吞吐量。
- 容災與一致性保障:采用多副本存儲與跨可用區部署,確保數據高可用;通過分布式事務(如Seata)或最終一致性方案,維護訂單狀態的一致性。
三、實踐案例與優化效果
以某頭部電商平臺為例,其通過上述方案在雙11期間實現了:
- 訂單處理峰值達100萬/秒,平均延遲低于50毫秒;
- 存儲系統可用性達99.99%,數據丟失率為零;
- 動態擴縮容節省30%資源成本。
雙11物流訂單的實時處理與存儲需以彈性架構為基礎,結合流式計算與智能存儲策略,方能平衡性能、成本與可靠性,為消費者提供無縫物流體驗。