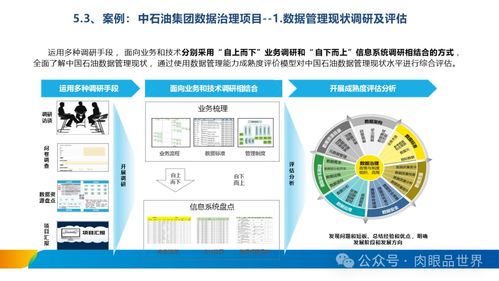
隨著大數據和云計算技術的快速發展,企業對數據處理和存儲的需求日益增長。分布式存儲與離線混部彈性計算平臺作為現代數據處理架構的重要組成部分,通過整合資源、優化調度,實現了高效、可靠的數據服務。本文將探討該平臺的實踐應用,重點分析其在數據處理和存儲服務方面的關鍵技術與優勢。
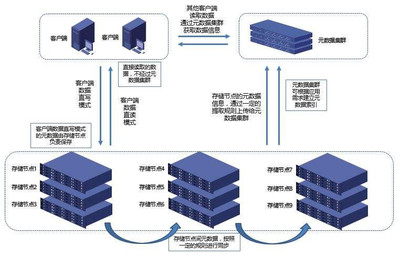
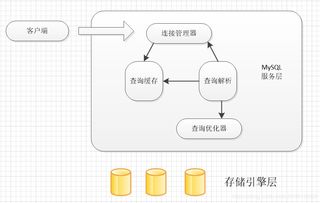
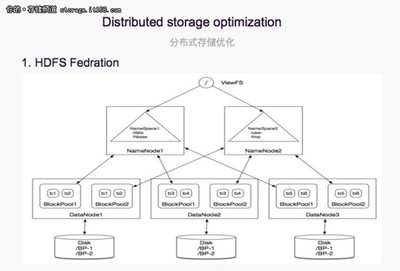
分布式存儲系統通過將數據分散存儲在多個節點上,提供了高可用性和可擴展性。例如,采用HDFS或Ceph等開源技術,企業能夠構建容錯性強、吞吐量高的存儲環境。這種架構不僅支持海量數據的持久化存儲,還通過冗余機制確保數據安全,避免了單點故障問題。
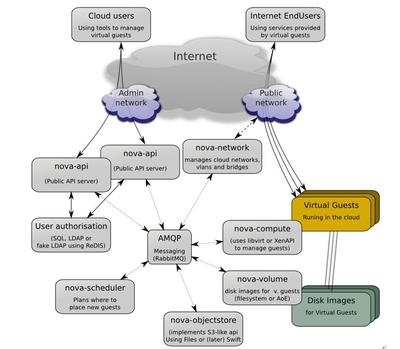
離線混部彈性計算平臺結合了離線批處理和在線實時計算的優勢,實現了資源的動態分配。在數據處理服務中,平臺利用容器化技術(如Kubernetes)將離線任務(如ETL作業)與在線服務(如API請求)混合部署在同一集群中。通過智能調度算法,平臺優先分配資源給高優先級的在線任務,同時在空閑時段處理離線任務,從而提升整體資源利用率。例如,阿里巴巴的Flink平臺在實踐中實現了高達80%的資源節省,同時保證了數據處理任務的及時完成。
在數據處理方面,該平臺支持多種計算框架,如Spark和Flink,用于執行復雜的ETL、數據清洗和分析任務。通過分布式計算,平臺能夠并行處理大規模數據集,顯著縮短處理時間。同時,與分布式存儲系統無縫集成,數據可直接從存儲層讀取和寫入,減少了網絡開銷,提高了效率。
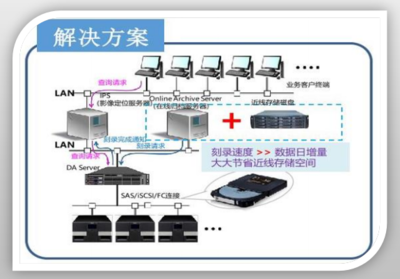
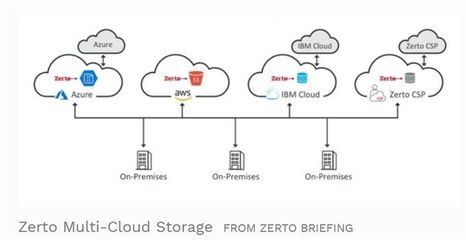
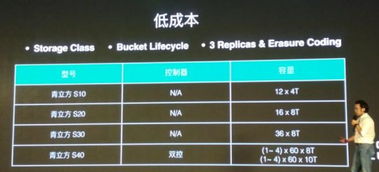
存儲服務方面,平臺提供統一的接口,支持多種數據格式(如Parquet、ORC)和訪問協議(如S3、HDFS),便于用戶靈活管理數據。結合數據生命周期管理策略,平臺自動將冷數據遷移到低成本存儲介質,如對象存儲,從而優化成本。實際案例中,騰訊云的TKE平臺通過離線混部技術,在數據處理任務中實現了存儲成本降低30%以上。
實踐過程中也面臨挑戰,如資源競爭、數據一致性保障和平臺運維復雜度。為解決這些問題,企業需引入監控工具(如Prometheus)和自動化運維流程,確保平臺的穩定運行。未來,隨著AI和邊緣計算的興起,分布式存儲與離線混部平臺將進一步演進,支持更智能的調度和跨地域數據處理。
分布式存儲與離線混部彈性計算平臺的實踐,不僅提升了數據處理和存儲服務的效率,還推動了企業數字化轉型。通過持續優化架構和算法,這一平臺將在未來數據驅動時代發揮更重要的作用。